
2023-2026.05 真实论文时间线复盘
如果你只看 pass@1,会觉得 RLVR 当然赢了;如果你把 pass@k、coverage、retention、steerability 一起放上来,结论就开始变复杂。
过去两年,后训练研究真正发生变化的,不是”谁更强”,而是”到底是谁在改模型的策略分布”。
结论:
SFT 在改外部数据集上的 token 分布,RL/RLVR 在改学生自己会访问到的 state distribution,OPD/OPSD 则是在 on-policy 状态上挂上更密的 teacher 信号。
所以这场争论的核心,不是 loss 名字,而是监督落在哪个分布上。
先把三者放到同一张图里
这也是为什么,近两年的争论越来越不像”RL 到底有没有用”,而更像”它到底是扩展了支持集,还是只把概率质量搬到了旧路径上”。
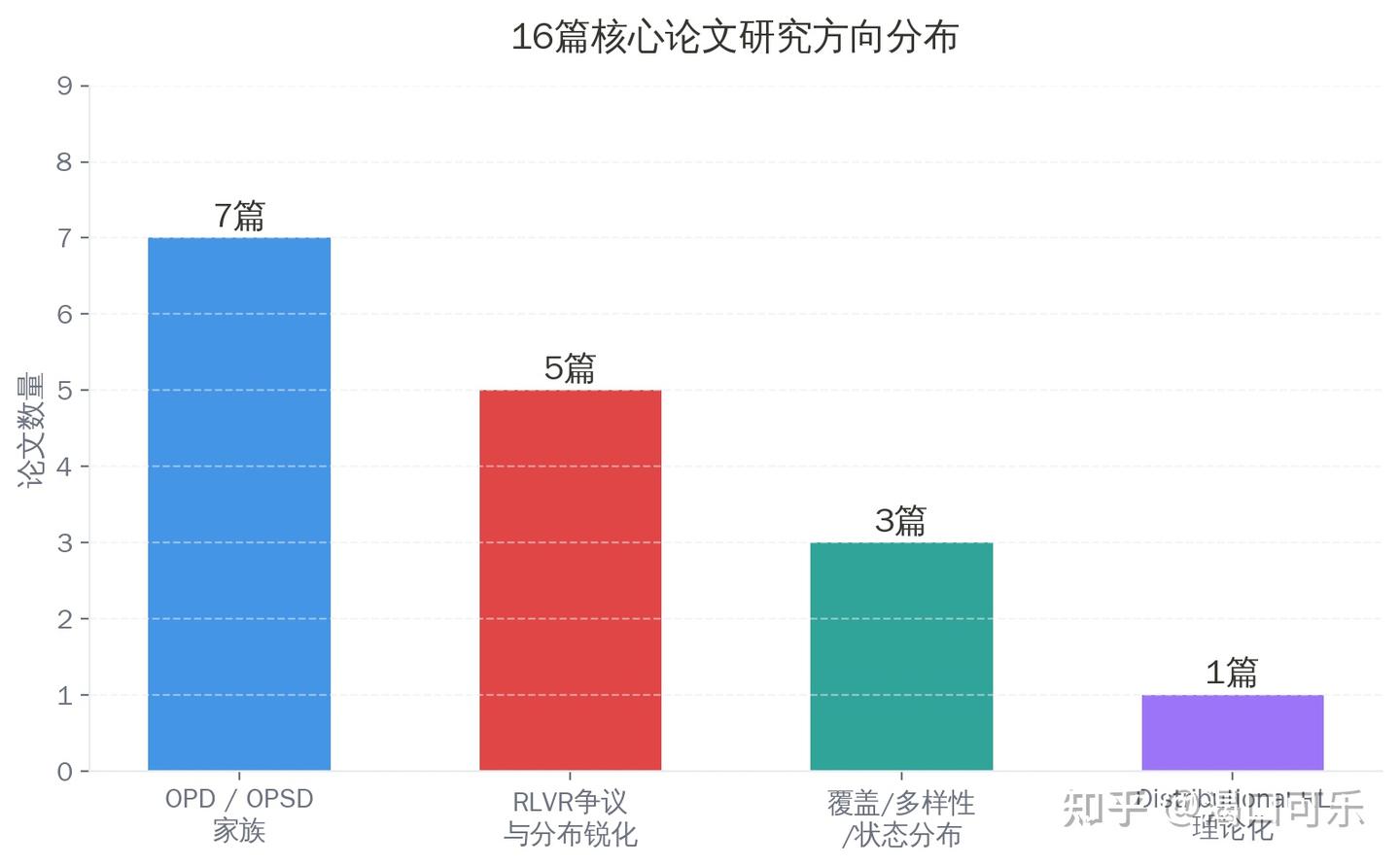
我核验到的相关论文,按研究方向统计
统计口径:只算与
SFT / RL / OPD分布争论直接相关、且可在一手来源核验到的论文。
截至2026-05-29,我核验到16篇直接相关代表作。
时间线:这场争论是怎么一路演化到今天的
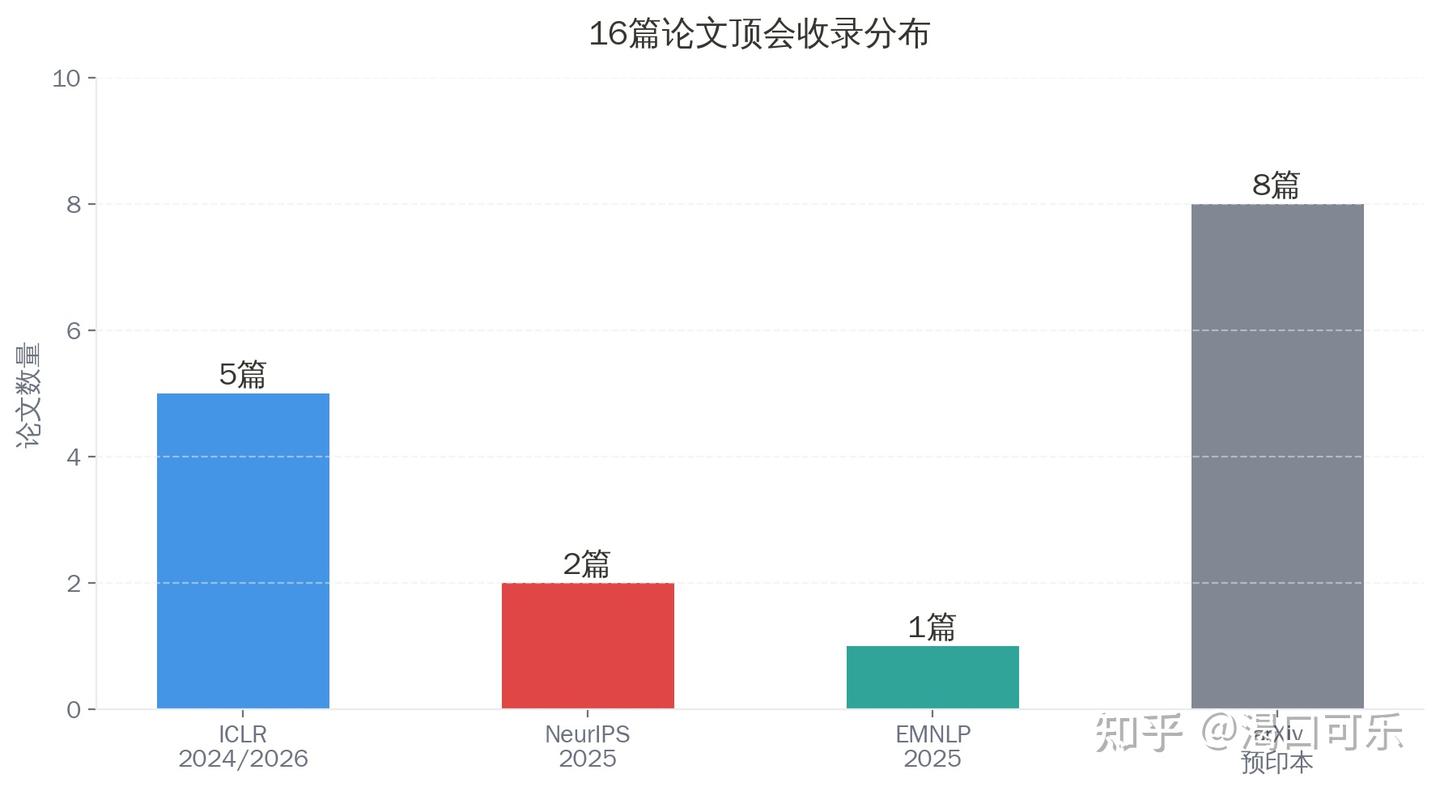
证据表:哪些论文真正改变了讨论方式
六维雷达图:SFT / RL / OPD 谁在哪个维度强
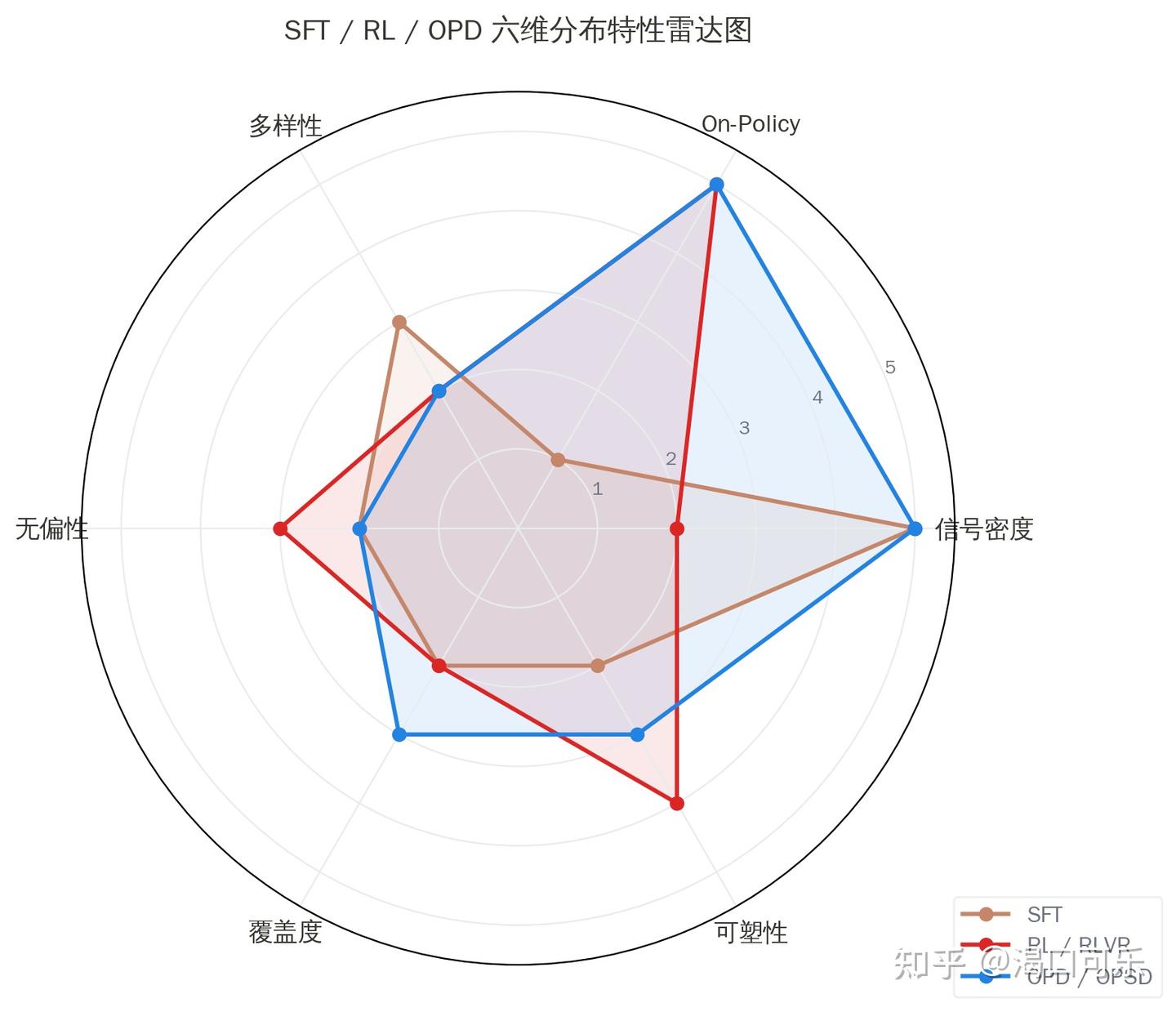
几个直观观察:
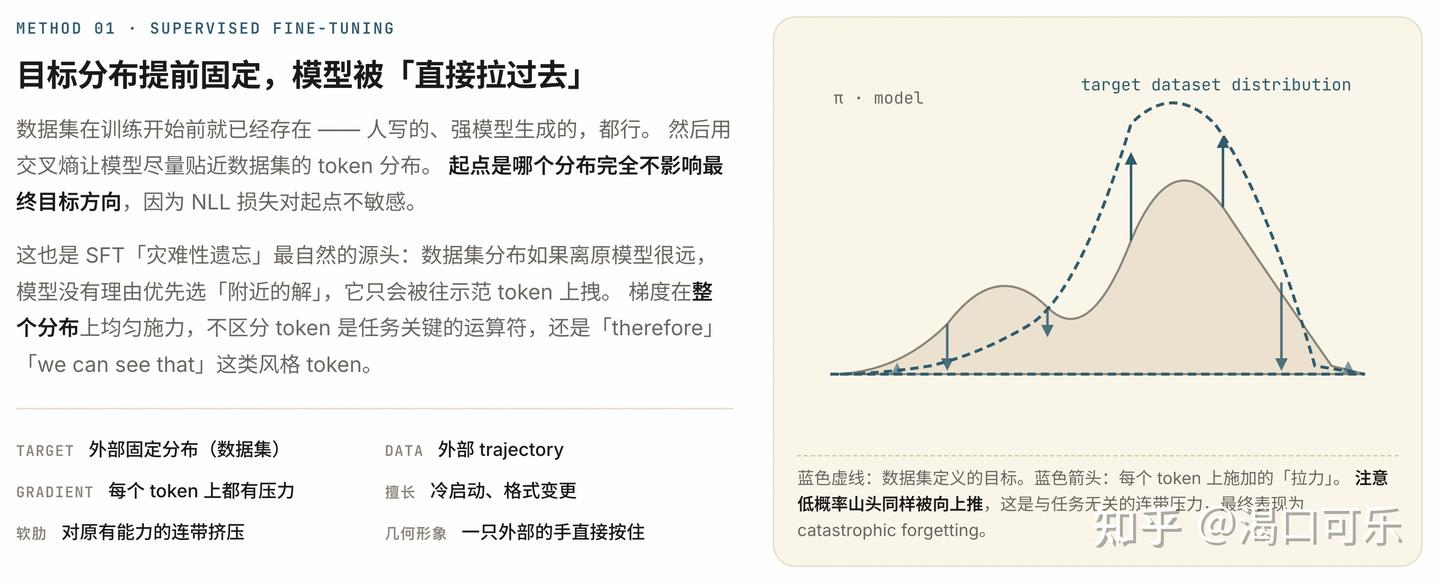
SFT 的致命短板是 off-policy——信号密度最高,但训练和推理的状态分布不匹配
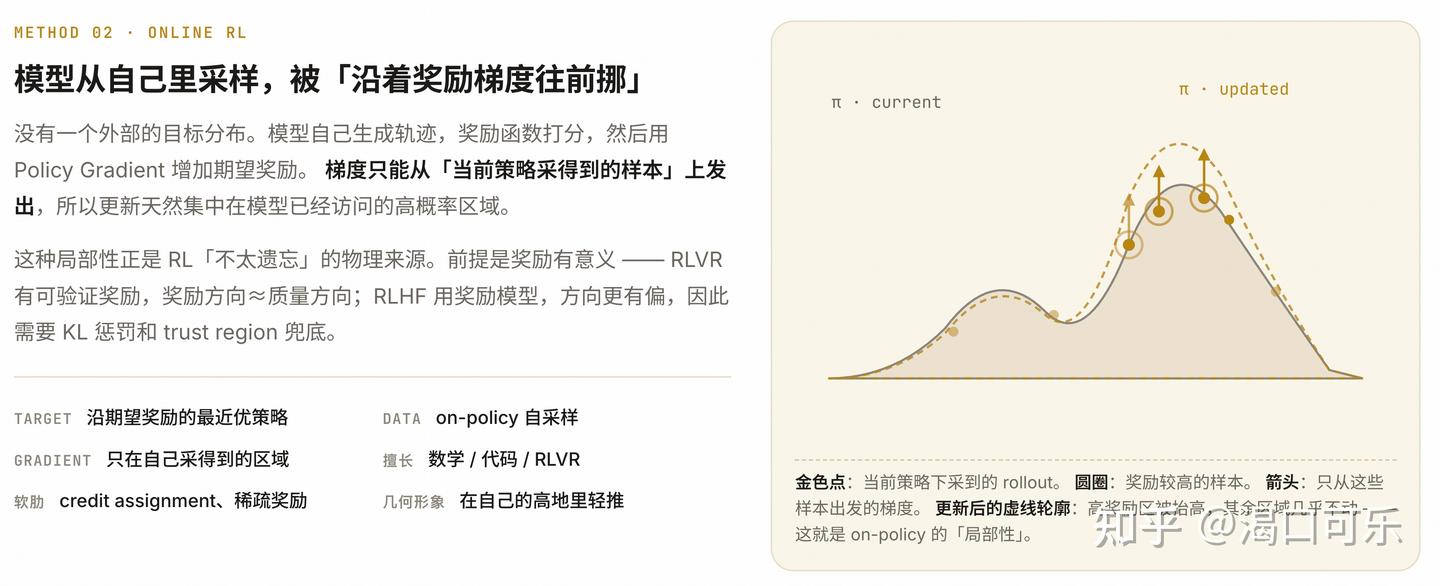
RL/RLVR 的致命短板是信号稀疏——on-policy 程度最高,但只有标量 reward,没有逐 token 指导
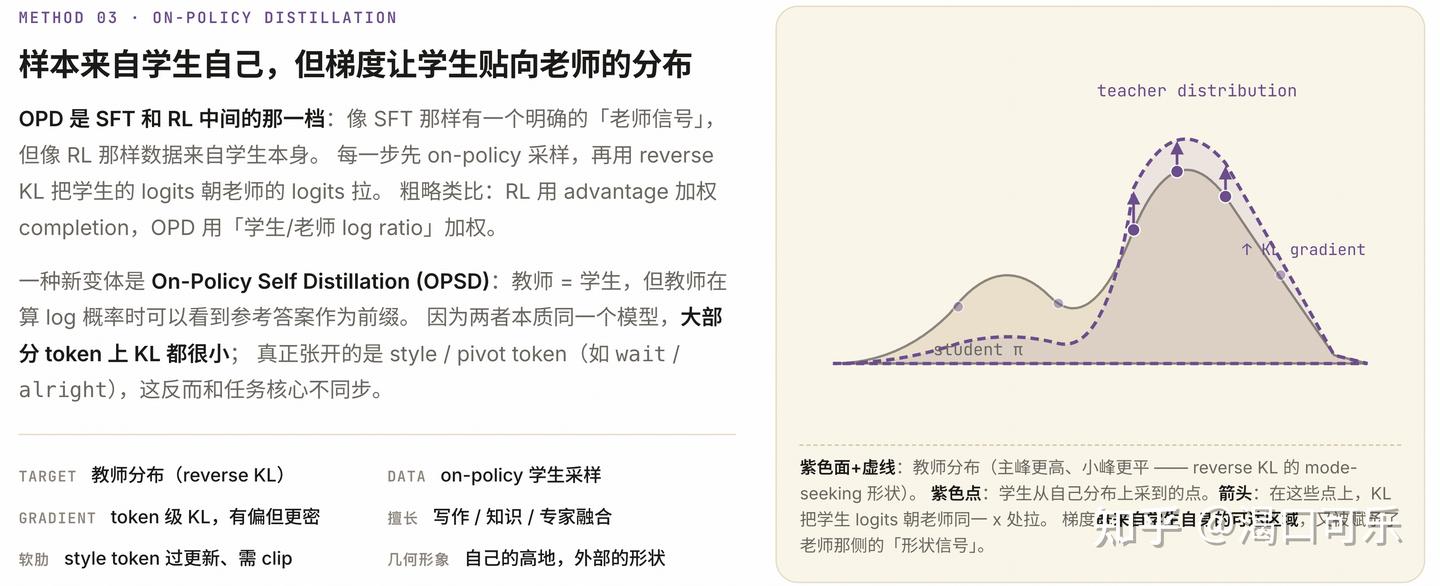
OPD/OPSD 看起来最均衡——但 2026 年 5 月的两篇论文敲了警钟:多样性可能比 RL 还差
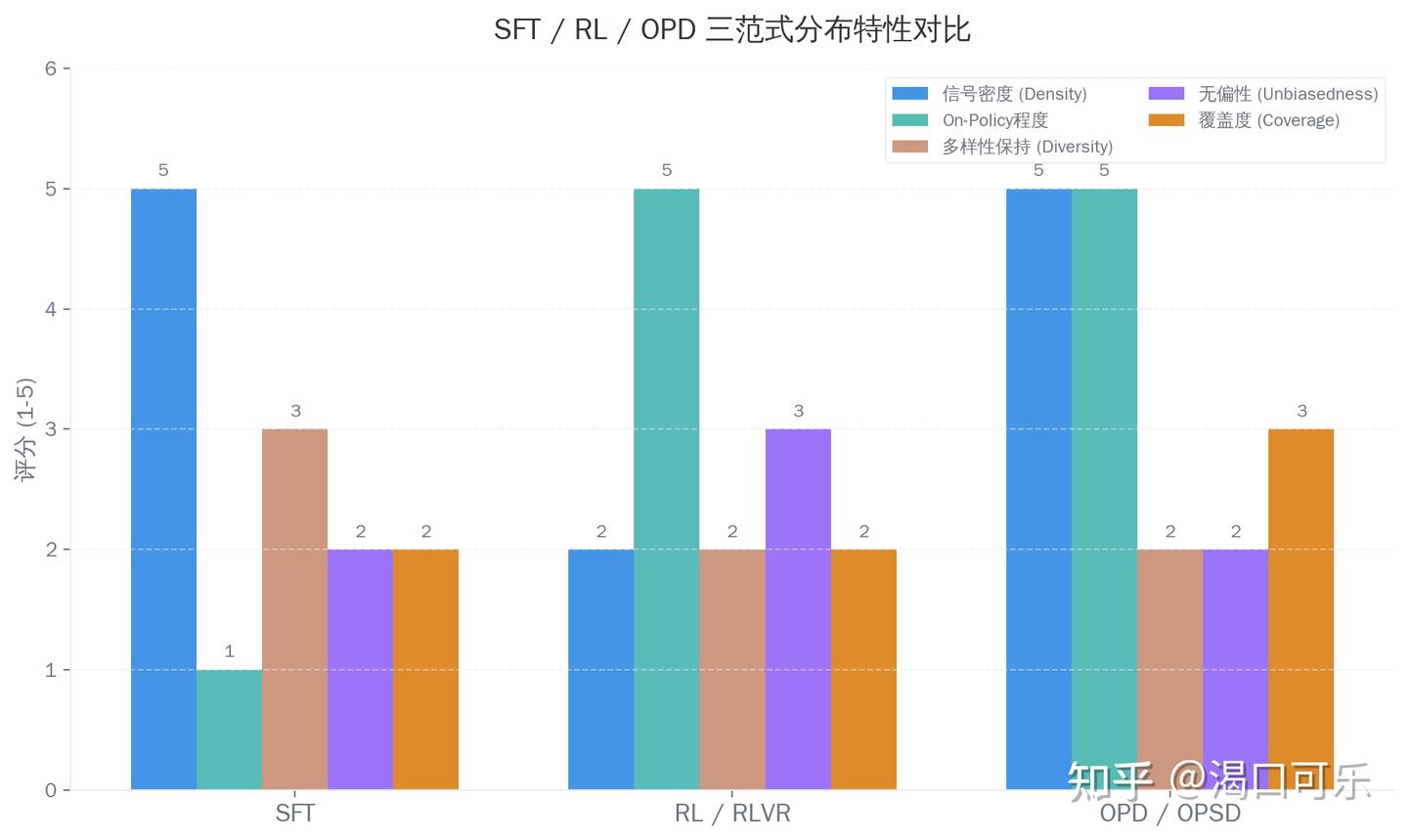
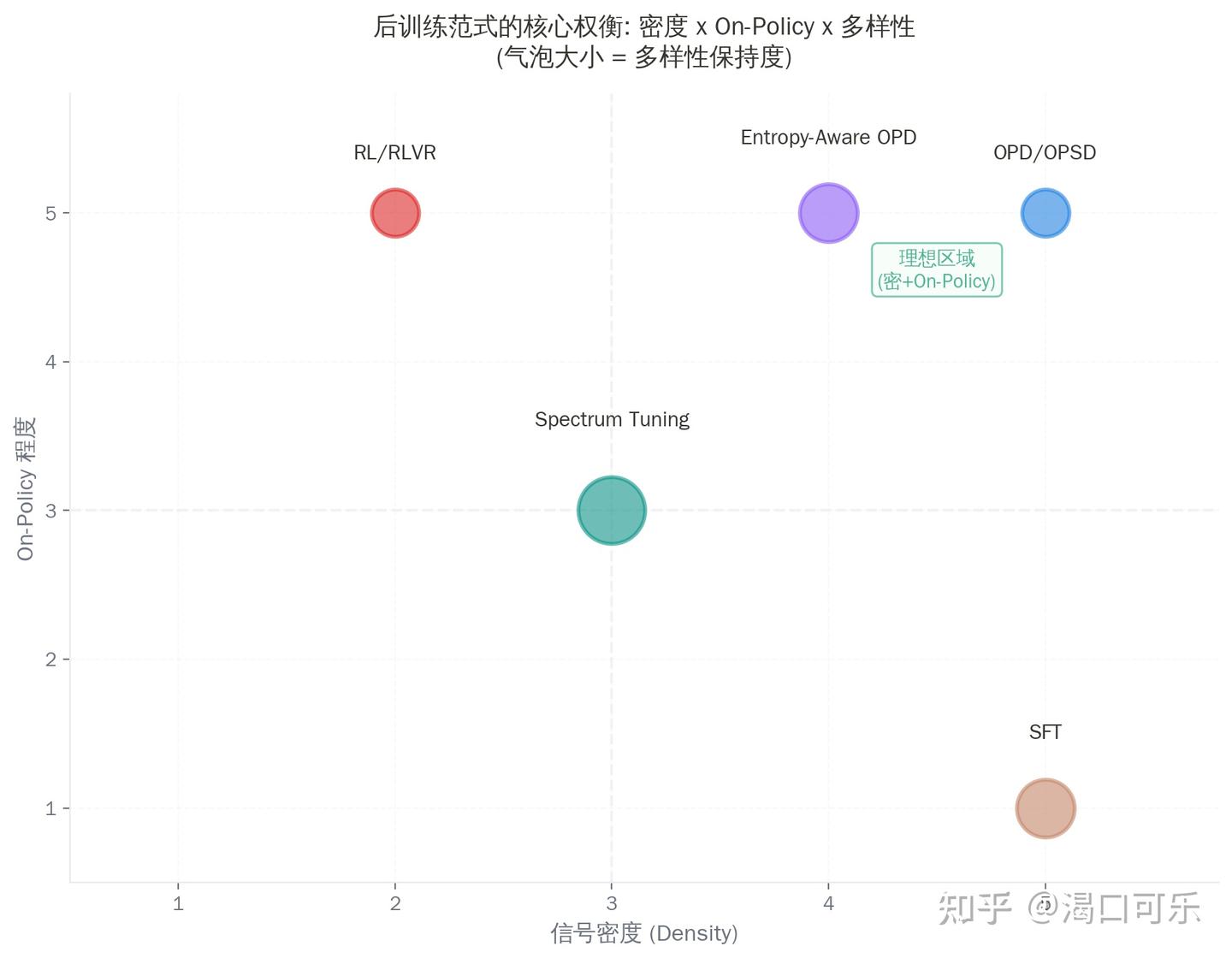
核心权衡:密度 x On-Policy x 多样性
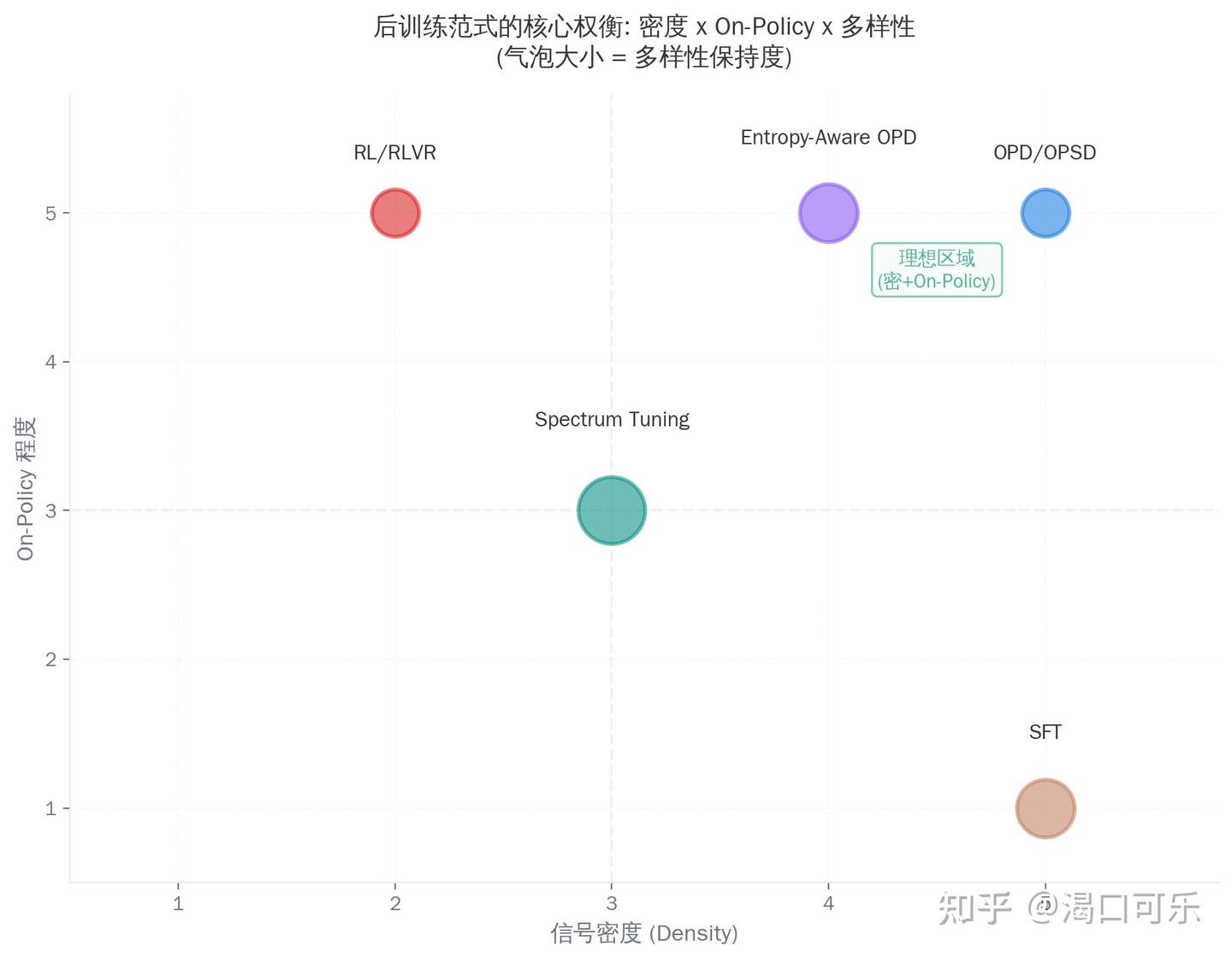
这张图是整篇文章最想传达的信息:
SFT:信号密,但 off-policy → 训练时学的状态,推理时碰不到
RL/RLVR:on-policy,但信号稀 → 只知道”这条路径好不好”,不知道”哪里好、哪里差”
OPD/OPSD:密 + on-policy → 看起来最理想,但多样性塌缩是真实风险
Spectrum Tuning 和 Entropy-Aware OPD:开始往右上角(理想区域)挪,但都只走了一步
未来最重要的方向,就是怎么同时拿到密度、on-policy、和多样性。
这条线的真实结论,已经慢慢收敛成什么样了?
1. RLVR 更像”分布重加权”,不是凭空发明新策略
这点是争论中心。Does RL Really Incentivize... 这类工作告诉我们,当前很多 RLVR 方法在大 k 上并没有显著扩大 base model 的支持集,更多是在已有路径里把正确答案的概率往上搬。Rewarding the Unlikely... 则进一步说明,GRPO 甚至可能偏爱”本来就更容易被采样到”的高概率证明,忽略低概率但正确的解。
2. 但 RLVR 也不是”只有分布锐化”
RLVR Implicitly Incentivizes... 的意义在于,它提醒我们不能只看最终答案。
如果加入 CoT-Pass@K,RLVR 在正确推理链上的改善会更清楚。
所以更准确的说法是:当前 RLVR 往往先改变概率质量分布,再逐步影响推理链质量;但它是否真的”扩展能力边界”,仍然依赖具体算法、训练长度和评估口径。
3. OPD / OPSD 的关键,不是 teacher 多强,而是 state 属于谁
OPD 系列论文有一个非常统一的信号:
只要训练发生在学生自己会访问的状态上,很多”老师与学生差很多”的现象都会被抹平。
这就是为什么 OPD 的学生有时会比 teacher 更稳,甚至在 retention 上超过 teacher。
换句话说,teacher 负责给信号,state distribution 负责决定信号打到哪里。
4. 后训练未来真正的战场,是 density × unbiasedness × on-policy × diversity
现在的各条路线,基本都只占了其中两项:
SFT:密,但 off-policy。RL/RLVR:on-policy,但稀疏。OPD:密,也 on-policy,但容易带来偏差和多样性塌缩。Spectrum Tuning和Whatever Remains...:开始把coverage和steerability当成最重要优化点。Entropy-Aware OPD和OVD:开始从工程上修补高 entropy、显存和对齐成本。
后训练的本质,已经从”改 token”变成”改 state distribution”。可以总结为三句话:
SFT、RL、OPD 的本质差别,不是”用什么 loss”,而是”监督落在哪个分布上”。
RLVR 当前更像在 base model 支持集内做概率重分配,是否能真正”发现新推理能力”,要看大
k、CoT-Pass@K和 diversity。未来最重要的指标,不会只有
pass@1,而会是pass@k + CoT-Pass@K + coverage + steerability + retention的组合。
参考文献
Agarwal, R., et al. “On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes.” ICLR 2024. 链接
Setlur, A., et al. “Rewarding the Unlikely: Lifting GRPO Beyond Distribution Sharpening.” EMNLP 2025. 链接
Yue, Y., et al. “Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?” NeurIPS 2025 Oral, AI4Math@ICML25 Oral. 链接
Wen, X., et al. “Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs.” ICLR 2026. 链接
“Quagmires in SFT-RL Post-Training: When High SFT Scores Mislead and What to Use Instead.” ICLR 2026. 链接
“Q#: Provably Optimal Distributional RL for LLM Post-Training.” NeurIPS 2025. 链接
“Spectrum Tuning: Post-Training for Distributional Coverage and In-Context Steerability.” ICLR 2026. 链接
“Whatever Remains Must Be True: Filtering Drives Reasoning in LLMs, Shaping Diversity.” ICLR 2026. 链接
“Black-Box On-Policy Distillation of Large Language Models.” arXiv:2511.10643, 2025. 链接
“OVD: On-policy Verbal Distillation.” arXiv:2601.21968, 2026. 链接
“Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models.” arXiv:2601.18734, 2026. 链接
“Fast and Effective On-Policy Distillation from Reasoning Prefixes.” arXiv:2602.15260, 2026. 链接
“Entropy-Aware On-Policy Distillation of Language Models.” arXiv:2603.07079, 2026. 链接
“On-Policy Self-Distillation with Sampled Demonstrations Reduces Output Diversity.” ICLR 2026 submission. 链接
“Rethinking On-Policy Self-Distillation for Thinking Models.” ICLR 2026 submission. 链接
“Rethinking RL for LLM Reasoning: It’s Sparse Policy Selection, Not Capability Learning.” arXiv:2605.06241, 2026. 链接
“Post-Training is About States, Not Tokens: A State Distribution View of SFT, RL, and On-Policy Distillation.” arXiv:2605.22731, 2026. 链接
框架参考(非论文引用):
SFT, RL, and On-Policy Distillation Through a Distributional Lensnrehiew.github.io/blog/sft_rl_opd/